ChatGPT in DR SBAITSO
One of my first sound cards was a Sound Blaster, which was pretty mindblowing when all you had heard before it was an IBM PC speaker.

It came with a floppy disk with a bunch of different utilities, but the one I used the most was DR SBAITSO.

From the manual, “DR SBAITSO is a program that seems to act intelligently by responding to your queries and pretending to solve your personal problems.”
Sound familiar?
When I first tried ChatGPT, it gave off a lot of DR SBAITSO vibes, especially the way that it slowly typed back to you.
If you’ve never played with it, DR SBAITSO is sort of a weird mash up between ELIZA and a Speak-and-Spell. Here it is embedded in this post, because we’re living in the future:
DR SBAITSO was never very convincing. If you spent any amount of time with it, you could tell it was just deflecting.
But it got me wondering, what if we replaced the internals of DR SBAITSO with ChatGPT but kept the weird synthesized voice?
Once again, we do things not because they are easy, but because we thought they were going to be easy.
Emulating an IBM PC
I recently came across a project called 86Box which emulates entire IBM PC systems and thought it might be fun to try it out.
First I started with a 386 SX, changed my mind and upgraded it to a 486 DX2/66 and then thought, “Well, am I not made of virtual money?” and then upgraded it one final time to a Pentium 200 with 16 megs of RAM.
DOSBox-X just drops you into DOS but with 86Box you get the full bootup experience:
I added a 500 MB hard drive, installed MS-DOS v6.22 from 3 floppy disk images and it was up and running.
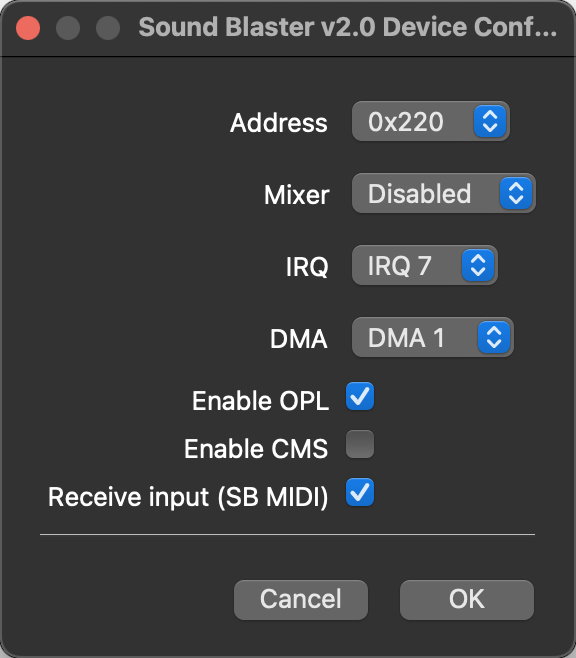
It was pretty easy to add a Sound Blaster card, here’s a Sound Blaster 2.0 that I configured:
90’s kids will remember that the next step is to add:
SET BLASTER=A220 I7 D1 T3
to the AUTOEXEC.BAT. This is an environment variable that tells programs the settings of the sound card, most importantly the IRQ that it’s on.
Next, I copied the contents of the Sound Blaster utilies floppy to C:\SB. DR SBAITSO actually relies upon a memory resident module called SBTALKER, which does the actual text-to-speech synthesis. So after running SBTALK.BAT to load that into memory, I ran SBAITSO2.EXE (because it’s v2.20?) and it was working fine.
As far as I know, the source code for DR SBAITSO has never been released, but alongside the SBTALKER module there is a utility called SAY.EXE, which can say whatever you want from a text file or as a command-line parameter. So if we can recreate the frontend of DR SBAITSO, we can use that utility to output the actual synthesized voice.
At this point we have a few options - we could recreate the frontend in DOS, or we can write it on a modern computer and have it communicate to the emulated machine just for the text-to-speech synthesis. Since the frontend has to communicate with ChatGPT as well, I opted for the latter.
In order to bridge the emulated IBM PC to my host computer, I added a Novell NE2000 network card.
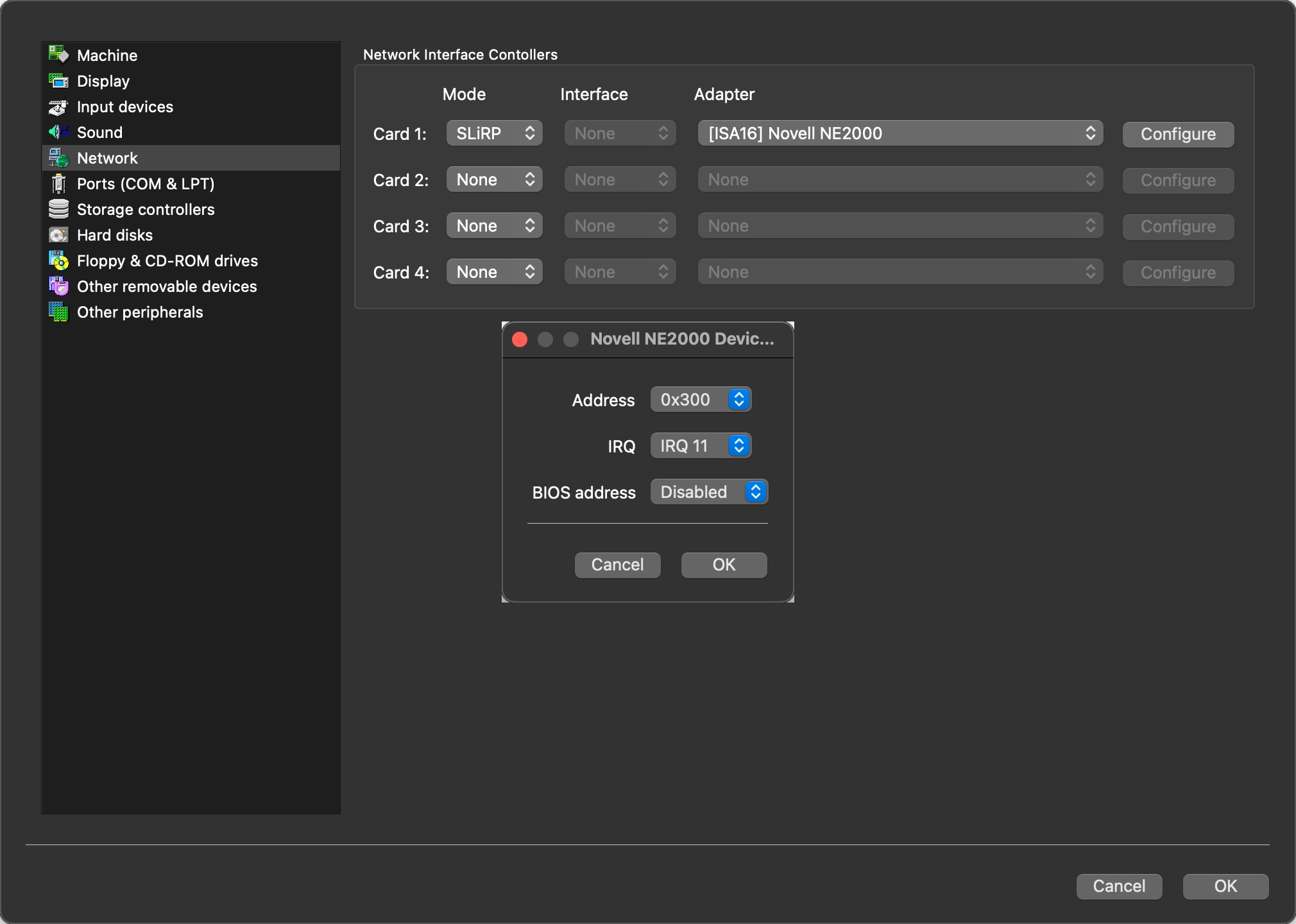
Next we’ll need packet drivers, you can find the driver for the NE2000 here. I copied the NE2000.COM driver to C:\DOS\DRIVERS and added this to my AUTOEXEC.BAT:
LH C:\DOS\DRIVERS\NE2000.COM 0x60 11 0x300
Make sure it matches the IRQ that you specified when configuring the card. In order to create a bridged network, we have to configure port forwarding, which can be done by adding these lines to 86box.cfg while the emulated machine is off:
[SLiRP Port Forwarding #1]
0_protocol = tcp
0_external = 2048
0_internal = 2048
1_protocol = tcp
1_external = 2049
1_internal = 2049
This sets it up so that the two machines essentially share ports 2048 and 2049 - data sent from the emulated machine can be received on the same port on the host machine and vice-versa.
Finally, we need some sort of program to transfer data between the two. I found mTCP, which is a set of programs for DOS that provide basic functionality like FTP, HTGET (essentially wget/curl for DOS), NC, and PING.
To configure MTCP, we create a copy of the example configuration in C:\MTCP\MTCP.CFG and add this to our AUTOEXEC.BAT:
SET MTCPCFG=C:\MTCP\MTCP.CFG
Finally, we test that it can leverage the packet driver by running DHCP.EXE.
Initially, I figured I could set up a web server on the emulated machine and one on the host machine and send HTTP calls from one to another, but if all the web server on the emulated machine was going to do was shell out to the text-to-speech program, it seemed like overkill. I decided instead to write a batch file LOOP.BAT that looks like this:
@ECHO OFF
del line.txt
:loop
nc -listen 2048 > line.txt
say line.txt
echo OK | nc -target 127.0.0.1 2049
goto loop
What this does is starts a netcat server, waiting for data. When it receives it, it writes it to line.txt and then calls the text-to-speech program to read that file. Afterwards, it starts a netcat client and signals to the host machine that it’s done talking and starts over again waiting for netcat data.
I tested it by running nc on my host machine, like this:
echo "HELLO WORLD" | nc localhost 2048
and confirmed that the Sound Blaster said that in the DR SBAITSO voice.
The Frontend
Next I got to work on building the frontend. In order for the frontend to be convincing, ideally it should use an IBM PC font. Luckily, a font pack for modern computers exists, this is the font I ended up using - specifically the one labeled Mx437 IBM VGA 9x16.
I changed iTerm2 to use the font, set to columns and rows to 80x25, and started looking up the ASCII codes for the box drawing characters. I found a library that handled ANSI escape codes and managed to make a pretty convincing replica of the original DOS program.
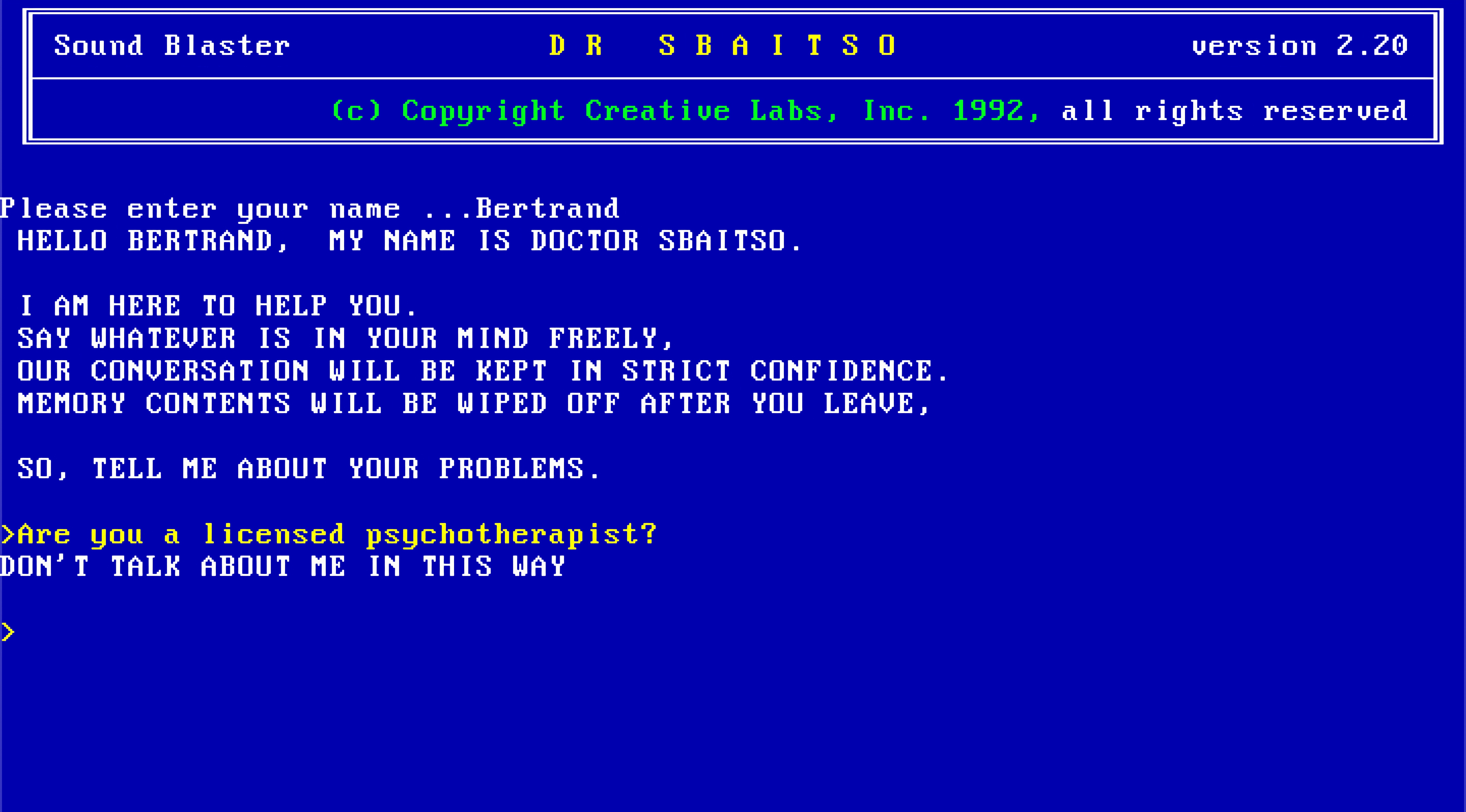
One of the things DR SBAITSO does when it first starts up is that it asks you for your name. Each character that you type of your name is spoken by the text-to-speech synthesizer. Since the loop from the host to the emulated machine back to the host takes a while, I found it difficult to have it go fast enough to keep up with the user typing. You’ll notice this problem even on the original program, it lags a lot, but in my frontend it was even worse. In order to overcome this, I launched DR SBAITSO in DOSBox-X and started recording the audio output. Then I typed every letter (A-Z), edited the recording in Audacity and exported 26 different .WAV files, one for each letter. When you type the letters for your name, it just plays the wav files, but the actual conversation text-to-speech synthesis is handled through the emulated machine.
Integrating with ChatGPT
The next part, integrating with ChatGPT, was surprisingly easy. OpenAI hasn’t released a public API yet, but a number of folks have reversed engineered how the API calls are made from their web frontend. Since these API calls end up costing OpenAI money, there is a bit of a cat-and-mouse game between the folks writing the libraries to interact with the ChatGPT API and OpenAI. The most recent development is a Cloudflare CAPTCHA - the library authors have in turn used puppeteer to log-in to OpenAI in a browser and automatically solve the CAPTCHA using a CAPTCHA-solving service if one appears.
One quirk of the ChatGPT API library that I chose is that it logs in to OpenAI each time, increasing the probability that I’ll hit a CAPTCHA for my IP address, so I wrapped it in a web service that I can send POST requests to and it’ll proxy them to OpenAI and return the response. This way I can restart my frontend as much as I want without having to re-authenticate with OpenAI.
Bringing it all together
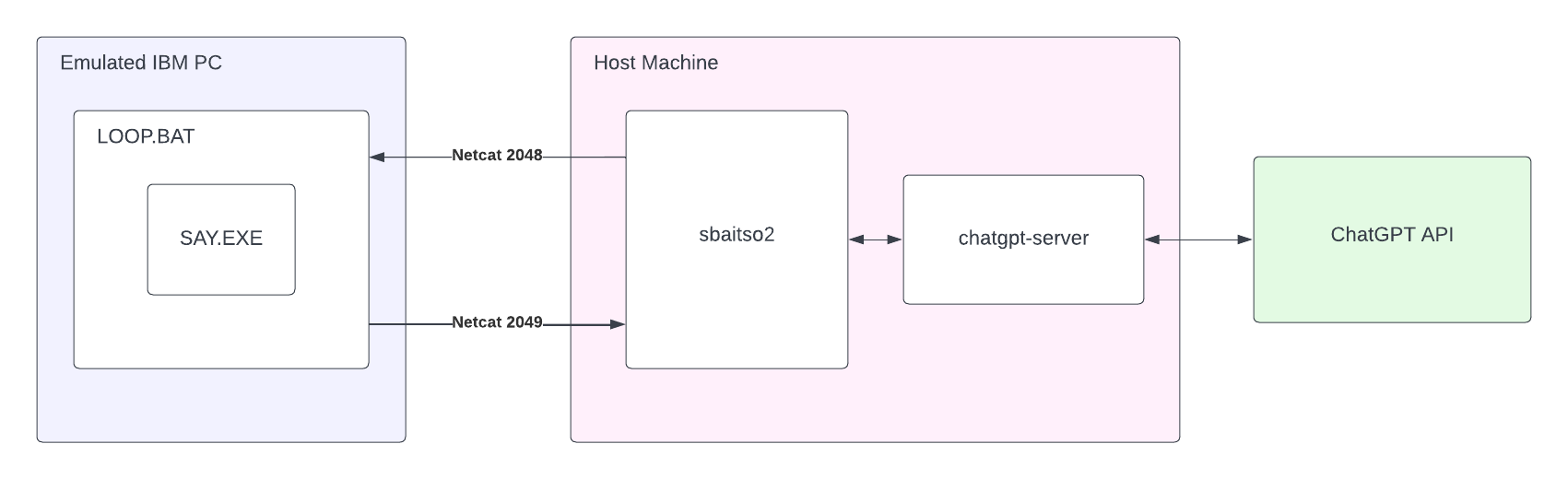
The sbaitso2 program displays the introduction and asks for the user’s name, buffering the characters that the user types and playing each character’s WAV file when pressed. After the user hits ENTER, it inserts the name into its initial prompt and sends the payload, line by line, to the emulated machine over netcat. After the emulated machine says the line, it sends a netcat ping back to the host machine, which then resumes to the next line. Next it takes the input from the user and sends it to chatgpt-server, which in turns sends it to the ChatGPT API and returns the response. The response is word wrapped to 80 characters and sent, line by line, to the emulated machine to synthesize the speech.
And that’s how you smoosh together two AIs that were written 30 years apart!
Source code is available here.